



Arquitectura y base de datos de Instagram: cómo almacena y busca miles de millones de imágenes
SISTEMAS DISTRIBUIDOSArquitectura y base de datos de Instagram: cómo almacena y busca miles de millones de imágenes Shivang 7 minutos de lectura
Instagram es la red social orientada a la fotografía más popular del planeta en la actualidad. Con más de mil millones de usuarios, se ha convertido en la primera opción para que las empresas ejecuten sus campañas de marketing.
Este artículo es una inmersión profunda en la arquitectura de su plataforma y aborda preguntas como ¿qué tecnologías utiliza en el backend? ¿Cuáles son las bases de datos que aprovecha la plataforma? ¿Cómo almacena miles de millones de fotos que atienden millones de consultas QPS por segundo? ¿Cómo busca contenido en los datos masivos que tiene?
1. ¿Qué tecnología usa Instagram en el backend?
El código del lado del servidor funciona con Django Python . Todos los servidores web y asíncronos se ejecutan en un entorno distribuido y no tienen estado.
El siguiente diagrama muestra la arquitectura de Instagram.
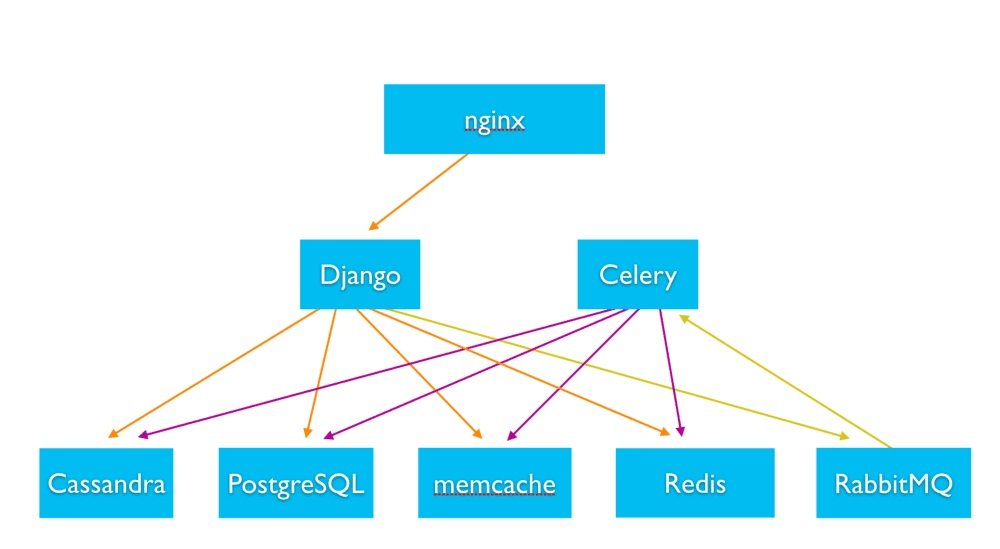
El backend utiliza varias tecnologías de almacenamiento como Cassandra, PostgreSQL, Memcache, Redis para brindar contenido personalizado a los usuarios.
Comportamiento asíncrono
RabbitMQ y Celery manejan tareas asincrónicas, como enviar notificaciones a los usuarios y otros procesos en segundo plano del sistema.
Celery es una cola de tareas asíncrona basada en la comunicación de mensajes distribuidos, enfocada en operaciones en tiempo real. También es compatible con la programación. El intermediario de mensajes recomendado para el apio es RabbitMQ.
RabbitMQ , por otro lado, es un popular agente de mensajes de código abierto escrito con el protocolo de cola de mensajería avanzada AMQP.
Gearman se utiliza para distribuir tareas entre varios nodos del sistema. Además, para el manejo de tareas asincrónicas, como cargas de medios, etc. Es un marco de aplicación para distribuir tareas a otras máquinas o procesos que son más aptos para ejecutar esas tareas en particular. Tiene una gama de aplicaciones que van desde sitios web de alta disponibilidad hasta el transporte de eventos de respaldo de bases de datos.
La pista de aprendizaje Zero to Software/Application Architect es una serie de cuatro cursos que estoy escribiendo con el objetivo de educarlo, paso a paso, en el dominio de la arquitectura de software y el diseño de sistemas distribuidos. La ruta de aprendizaje lo lleva desde no tener conocimiento hasta convertirlo en un profesional en el diseño de sistemas distribuidos a gran escala como YouTube , Netflix, Google Stadia, etc. Compruébalo .
Computación de HashTags de tendencias en la plataforma
El backend de tendencias es una aplicación de procesamiento de flujo que contiene cuatro nodos/componentes conectados linealmente.
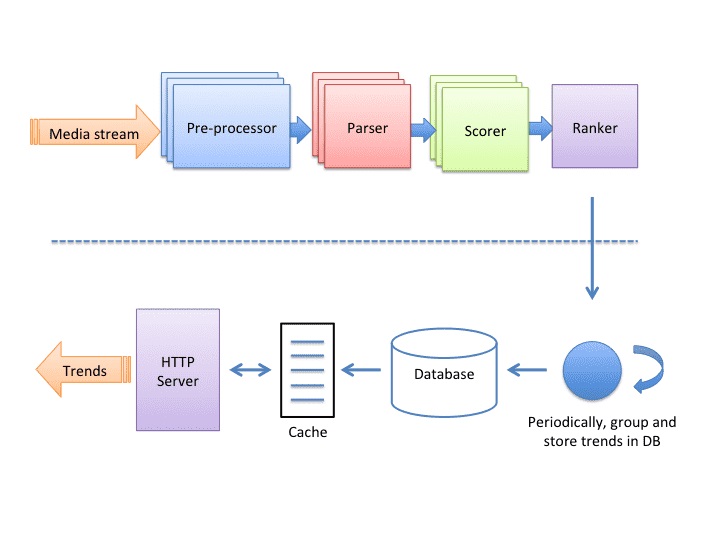
La función de los nodos es consumir un flujo de registros de eventos y producir la lista clasificada de contenido de tendencia, es decir, hashtags y lugares.
Nodo de preprocesador
El nodo del preprocesador adjunta los datos necesarios para aplicar filtros en los medios originales que tienen metadatos adjuntos.
Nodo analizador
El nodo analizador extrae todos los hashtags adjuntos con una imagen y le aplica filtros.
Nodo marcador
El nodo Scorer realiza un seguimiento de los contadores de cada hashtag en función del tiempo. Todos los datos del contador se guardan en la memoria caché, también se conservan para mayor durabilidad.
Nodo de clasificación
La función del nodo de clasificación es calcular las puntuaciones de tendencia de los hashtags. Las tendencias se sirven desde un caché de lectura que es Memcache y la base de datos es Postgres.
Para educarse en la arquitectura de software de los recursos adecuados, para dominar el arte de diseñar sistemas distribuidos a gran escala que escalarían a millones de usuarios, para comprender qué buscan realmente las empresas de tecnología en un candidato durante sus entrevistas de diseño de sistemas. Lea la publicación de mi blog sobre el diseño del sistema maestro para sus entrevistas o inicio web.
Bases de datos utilizadas @Instagram
PostgreSQL es la base de datos principal de la aplicación, almacena la mayoría de los datos de la plataforma, como datos de usuario, fotos, etiquetas, metaetiquetas, etc.
A medida que la plataforma ganó popularidad y los datos crecieron enormemente con el tiempo, el equipo de ingeniería de Insta meditó sobre diferentes soluciones NoSQL para escalar y finalmente decidió fragmentar la base de datos PostgreSQL existente según se adaptara mejor a sus requisitos.
Hablando de escalar la base de datos mediante fragmentación y otros medios, este artículo Base de datos de YouTube: ¿cómo almacena tantos videos sin quedarse sin espacio de almacenamiento? es una lectura interesante.
Por lo tanto, el clúster de la base de datos principal de Instagram contiene 12 réplicas en diferentes zonas e involucra 12 instancias de memoria extra grandes cuádruples.
Hive se utiliza para el archivo de datos. Es un software de almacenamiento de datos creado sobre Apache Hadoop para capacidades de análisis y consulta de datos. Un proceso por lotes programado se ejecuta a intervalos regulares para archivar datos de PostgreSQL DB a Hive .
Vmtouch , una herramienta para conocer y administrar el caché del sistema de archivos de Unix y servidores similares a Unix , se utiliza para administrar datos en memoria cuando se mueve de una máquina a otra.
El uso de Pgbouncer para agrupar conexiones de PostgreSQL al conectarse con el servidor web back-end resultó en un gran aumento del rendimiento.
Redis es una base de datos en memoria que se utiliza para almacenar el feed de actividad, las sesiones y otros datos en tiempo real de la aplicación.
Memcache , un sistema de almacenamiento en caché de memoria distribuida de código abierto, se utiliza para el almacenamiento en caché en todo el servicio.
Gestión de datos en el clúster
Los datos en todo el clúster finalmente son consistentes , los niveles de caché se ubican junto con los servidores web en el mismo centro de datos para evitar la latencia.
Los datos se clasifican en datos globales y locales, lo que ayuda al equipo a escalar. Los datos globales se replican en diferentes centros de datos en las zonas geográficas. Por otro lado, los datos locales se limitan a centros de datos específicos.
Inicialmente, el backend de la aplicación estaba alojado en los servicios web de AWS Amazon, pero luego se migró a los centros de datos de Facebook . Eso facilitó la integración de Instagram con otros servicios de Facebook, redujo la latencia y aprovechó los marcos, herramientas para implementaciones a gran escala creadas por el equipo de ingeniería de Facebook.